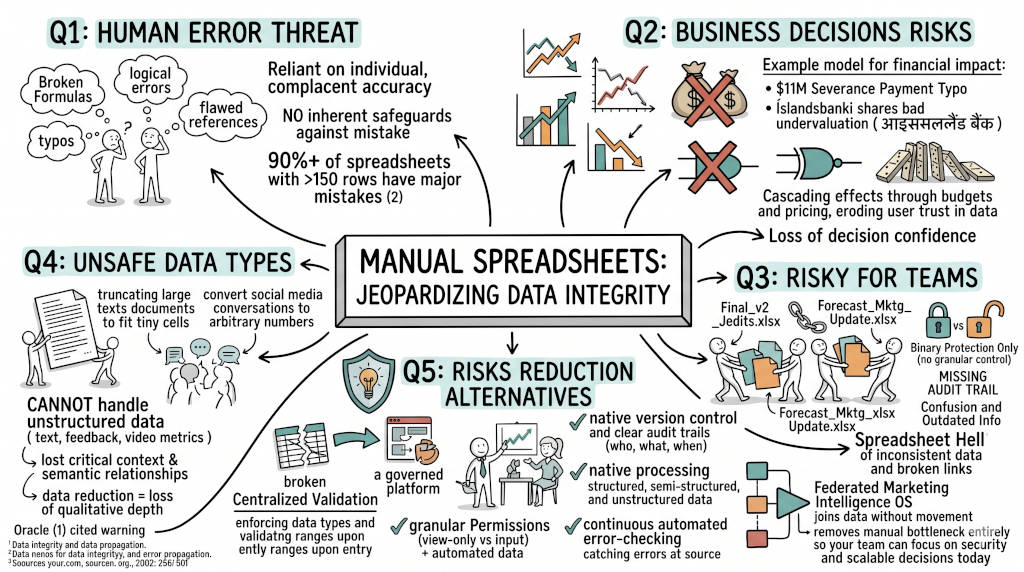
Summary: Manual spreadsheets jeopardize data integrity through human errors, poor version control, and lack of governance, leading to costly mistakes like the $11 million severance payout and £16 million bank undervaluation. Risks amplify in teams due to conflicting versions and absent audit trails, while spreadsheets struggle with unstructured data types. Alternatives include governed analytics platforms offering centralized validation, automated error‑checking, granular access controls, and native handling of diverse data. For marketers, a Federated Marketing Intelligence OS connects sources without movement, resolves identities automatically, and delivers trusted answers, eliminating spreadsheet‑based risks while enabling scalable, secure decision‑making and fostering data‑driven confidence in organizational decision‑making today.
Q1: What makes manual spreadsheets a threat to data integrity?
The Answer: Manual spreadsheets rely on human entry and manipulation, which introduces errors that compromise data accuracy at multiple levels. Research consistently shows that spreadsheets are error-prone, with studies indicating that 90% of spreadsheets containing over 150 rows have at least one major mistake (2). These errors aren't limited to simple typos—they include flawed formulas, incorrect cell references, broken links between sheets, and logical errors in complex calculations that can go undetected for months or even years.
The Human Error Factor
The fundamental issue is that spreadsheets place the burden of accuracy entirely on the user. Unlike database systems with built-in validation rules or analytics platforms with automated error-checking, spreadsheets offer no inherent safeguards against human mistake. Users must manually verify every entry, every formula, and every assumption—a process that is both time-consuming and inherently fallible.
Compounding this problem is the psychological factor: users tend to develop overconfidence in spreadsheet accuracy. As Thorne (2) notes, "Many of us don’t consider spreadsheets to warrant serious consideration. This means we become complacent and assume there is no need to test, validate or verify our work." This false sense of security means errors often remain undiscovered until they cause significant business harm, such as incorrect financial reporting, flawed forecasting, or misguided strategic decisions.
Version Control Nightmares
Furthermore, the manual nature of spreadsheet work creates version control nightmares. When multiple team members need to update or reference the same data, files get copied, renamed, and saved in different locations, leading to conflicting versions where it's impossible to determine which contains the "correct" data. Without centralized governance or audit trails, organizations lose the ability to verify data lineage or reconstruct how specific figures were derived.
Q2: How do spreadsheet errors affect business decisions?
The Answer: When spreadsheets contain errors—whether from data entry mistakes, formula flaws, or outdated information—the insights derived from them become fundamentally unreliable, leading to poor strategic choices with tangible business consequences. The impact isn't theoretical; real-world cases demonstrate how spreadsheet errors translate directly into financial losses, operational failures, and reputational damage.
Real-World Financial Impact
Consider the case of a major U.S. manufacturer that suffered an $11 million severance payout error due to a single typo in a spreadsheet (1). The mistake occurred during annual compensation planning when an analyst accidentally added an extra zero to a severance calculation. The error went unnoticed through multiple review cycles and was only discovered after the incorrect payments had already been processed, forcing the company to pursue costly recovery efforts while damaging employee trust.
Even more striking is the example of Íslandsbanki, a state-owned Icelandic bank, which sold a portion of shares that were badly undervalued due to a spreadsheet error in 2022 (2). When consolidating assets from different spreadsheets for the sale, the bank failed to properly "clean" and format the data—specifically, not removing duplicate entries and inconsistent formatting across source sheets. This seemingly minor oversight resulted in the bank's shares being undervalued by as much as £16 million, representing a massive loss of shareholder value that could have been prevented with basic data validation procedures.
Cascade Effects and Compliance Risks
These examples illustrate how spreadsheet errors propagate through business processes: a single incorrect figure in an input sheet can cascade through dependent calculations, affecting budgets, forecasts, pricing strategies, and investment decisions. In regulated industries, such errors can also trigger compliance violations—for instance, when inaccurate financial data leads to incorrect tax filings or misleading investor reports. Beyond the immediate financial impact, repeated spreadsheet errors erode organizational trust in data, leading to what Oracle (1) describes as a "loss of confidence in the data and conclusions" that forces decision-makers to revert to intuition or anecdotal evidence rather than evidence-based analysis.
Q3: Why are spreadsheets especially risky when used across teams?
The Answer: Spreadsheets are inherently designed for individual use, making them particularly problematic when deployed in collaborative, multi-user environments. Unlike modern analytics platforms that feature built-in collaboration controls, version history, and permission settings, spreadsheets lack fundamental governance mechanisms needed for team-based data management. This architectural limitation creates several interconnected risks that compound as more users interact with the same files.
The Version Control Problem
The most immediate challenge is version control. When multiple team members need to update or reference a spreadsheet, the typical workflow involves creating copies ("Final_v2_Jedits.xlsx," "Forecast_Marketing_Update.xlsx," etc.) that quickly proliferate across shared drives, email attachments, and personal folders. As Oracle (1) explains, "With multiple users editing a single spreadsheet, keeping track of the most up-to-date version can be difficult. This can lead to confusion, and people might end up working with different spreadsheet versions." Without a centralized system to track changes or enforce a single source of truth, teams inevitably make decisions based on conflicting or outdated information.
Lack of Granular Access Controls
This fragmentation is exacerbated by the absence of granular access controls. Spreadsheets offer only binary protection options—either a file is completely locked (preventing any edits) or fully open (allowing anyone with access to modify any cell). There's no way to, for example, allow the sales team to update lead counts while preventing them from altering complex financial models, or to give analysts view-only access to sensitive compensation data. This all-or-nothing approach to security increases the risk of both accidental modifications and intentional data tampering.
Missing Audit Trail Capabilities
Furthermore, spreadsheets provide no native audit trail capabilities. When errors do occur in a team environment, it's nearly impossible to determine who made what change and when—critical information needed for error correction, accountability, and process improvement. As Tang, Sau-Fun (3) notes in their literature review on spreadsheet quality assurance, the lack of built-in governance features means organizations must rely on manual processes and trust-based systems that are inherently unreliable at scale.
The "Spreadsheet Hell" Phenomenon
The cumulative effect is what industry experts call "spreadsheet hell"—a state where organizations maintain dozens or hundreds of interconnected spreadsheet files with inconsistent data, broken links, and unknown error rates. In this environment, even simple questions like "What were our actual Q1 sales figures?" become exercises in forensic accounting rather than straightforward data retrieval, severely impeding organizational agility and decision speed.
Q4: Are there data types that spreadsheets cannot handle safely?
The Answer: While spreadsheets excel at handling structured numeric data and basic text, they present significant risks when used to manage or analyze more complex data types, particularly unstructured or semi-structured information that modern marketing and business operations increasingly rely on. This limitation isn't merely inconvenient—it actively threatens data integrity by forcing users to distort or oversimplify information in ways that lose critical context and introduce interpretation errors.
Structural Limitations
Spreadsheets are fundamentally organized around a two-dimensional grid of rows and columns, optimized for tabular numeric relationships. When confronted with data types that don't fit this model—such as lengthy customer feedback text, video engagement metrics, social media interactions, or multi-dimensional behavioral sequences—users must resort to problematic workarounds. Common approaches include truncating text to fit cell limits, creating arbitrary numbering systems for qualitative data, or separating related information across multiple sheets in ways that break semantic relationships.
For example, attempting to analyze open-ended survey responses in a spreadsheet often means either limiting responses to a certain character count (losing nuanced feedback) or splitting lengthy comments across multiple cells (destroying the contextual integrity of each response). Similarly, trying to track customer journey touchpoints across channels in a spreadsheet typically requires creating complex, brittle systems of cross-references that are prone to breaking when rows are inserted or deleted.
Explicit Warnings from Industry Experts
Oracle (1) explicitly warns about this limitation: "Spreadsheets are limited in handling data types important to analytics efforts, especially unstructured data, such as large text documents." This constraint becomes particularly problematic in marketing analytics, where valuable insights increasingly come from unstructured sources like customer service transcripts, product reviews, social media conversations, and behavioral web analytics. When these rich data sources are forced into spreadsheet format, the process of "data reduction" inherently sacrifices fidelity—converting qualitative depth into quantitative simplifications that may miss critical patterns or misleadingly represent complex realities.
Lack of Data Type Enforcement
Moreover, spreadsheets lack the data type enforcement capabilities of modern databases or analytics platforms. There's no way to ensure that a column designated for dates actually contains only valid date values, or that a field meant for currency amounts doesn't accidentally contain text entries. This flexibility, while useful in some ad-hoc scenarios, becomes a liability when data integrity is paramount, as it allows inconsistent data entry that undermines the reliability of any subsequent analysis.
Q5: What alternatives reduce the risk associated with manual spreadsheets?
The Answer: Organizations seeking to mitigate spreadsheet-related data integrity risks should adopt purpose-built analytics platforms that combine centralized data management, automated validation, and governed collaboration—capabilities that manual spreadsheets fundamentally lack. The most effective solutions address not just the symptoms of spreadsheet errors but their root causes by removing manual intervention from critical data processes while providing transparency and traceability throughout the analytics lifecycle.
Shift from File-Based to Platform-Based Workflows
At the core of this approach is a shift from file-based, manual workflows to platform-based, automated systems. Modern analytics platforms—including cloud-based business intelligence tools, dedicated data analysis software, and enterprise resource planning (ERP) systems—offer several key advantages over spreadsheets:
Centralized Data Repositories with Built-in Validation
First, they provide centralized data repositories with built-in validation rules. Rather than relying on users to manually verify every entry, these systems can enforce data types, validate ranges, check for duplicates, and flag anomalies automatically upon input. As Tang, Sau-Fun (3) emphasizes in their spreadsheet quality assurance literature review, moving validation "early in the spreadsheet life cycle" (i.e., at the point of data entry rather than through manual checking afterward) is significantly more effective at preventing errors than relying on detection after the fact.
Inherent Version Control and Audit Trails Second, these platforms offer inherent version control and audit trails. Every change to data or metadata is tracked with user attribution, timestamps, and the ability to revert to previous states—eliminating the version confusion that plagues spreadsheet environments. This capability not only helps prevent errors but also provides the forensic capability to investigate and correct them when they do occur.
Sophisticated Access Controls Third, they feature sophisticated access controls that go beyond spreadsheets' all-or-nothing approach. Administrators can define granular permissions—for example, allowing certain teams to input data while restricting others to view-only access, or enabling analysts to modify specific datasets while protecting core financial models from alteration. This precision reduces both accidental errors and intentional misuse risks.
Handling Diverse Data Types Fourth, modern platforms are designed to handle the diverse data types that challenge spreadsheets. They can natively process structured data (transactions, metrics), semi-structured data (JSON logs, XML feeds), and increasingly, unstructured data (text, images, video) through integrated natural language processing and multimedia analysis capabilities. This eliminates the need for dangerous data simplification workarounds that threaten integrity.
Automated Error-Checking Throughout Workflows Fifth, they provide automated error-checking throughout the analytical workflow. Rather than waiting for humans to spot mistakes in output reports, these platforms continuously validate calculations, trace data lineage, and flag inconsistencies in real-time—catching errors at the point of origin rather than allowing them to propagate through dependent analyses.
Marketing-Specific Solutions: Federated Marketing Intelligence OS
Specifically for marketing organizations, a Federated Marketing Intelligence OS—like the one offered by Data Research Analysis—combines these advantages with marketing-specific capabilities. It connects natively to marketing data sources (Google Ads, GA4, CRM systems, social platforms) without requiring data movement, automatically resolves identity relationships across channels, and serves validated answers through natural language interfaces—eliminating the manual data preparation and reconciliation steps that introduce so much error in spreadsheet-based workflows.
A Fundamental Shift in Data Governance Philosophy
The transition from spreadsheets to such platforms isn't merely a technological upgrade; it represents a fundamental shift in data governance philosophy—from hoping users will be perfect to designing systems that prevent, detect, and correct errors automatically regardless of user skill level or attention. As Oracle (1) concludes in their analysis of spreadsheet risks, organizations that adopt governed analytics platforms experience "reduced risks associated with spreadsheet usage" while gaining the scalability, security, and analytical depth needed for modern decision-making.
Ready to Eliminate Spreadsheet Risks?
Stop gambling with your data integrity. Manual spreadsheets create unnecessary exposure to errors, security vulnerabilities, and compliance risks that can cost your organization millions.
Data Research Analysis offers a Federated Marketing Intelligence OS that connects natively to your marketing data sources, automatically validates information, and provides governed collaboration—eliminating the manual processes that introduce risk.
Schedule a 15-minute strategy call to see how much hidden cost is embedded in your current spreadsheet-dependent workflows and what a unified intelligence layer would unlock for your team.
References
Oracle. (2023, June 5). 10 common spreadsheet risks and solutions for businesses. Retrieved May 13, 2026, from https://www.oracle.com/analytics/spreadsheet-risks/
Thorne, S. (2024, January 25). Spreadsheet errors can have disastrous consequences – yet we keep making the same mistakes. The Conversation. https://theconversation.com/spreadsheet-errors-can-have-disastrous-consequences-yet-we-keep-making-the-same-mistakes-219356
Tang, S.-F. (2024). Spreadsheet quality assurance: a literature review. Frontiers of Computer Science, 18, 182203. https://doi.org/10.1007/s11704-023-2384-6
Poon, P.-L., et al. (2024, August 13). Study finds 94% of business spreadsheets have critical errors. Phys.org. https://phys.org/news/2024-08-business-spreadsheets-critical-errors.html


